1.YARN介绍
Apache YARN(Yet Another Resource Negotiator 另一种资源管理系统 的缩写)是Hadoop的集群资源管理系统。YARN被引入在Hadoop 2,最初是为了改善MapReduce的实现,但它具有足够的通用性,同样可以支持其他的分布式计算模式(比如常用的spark)。
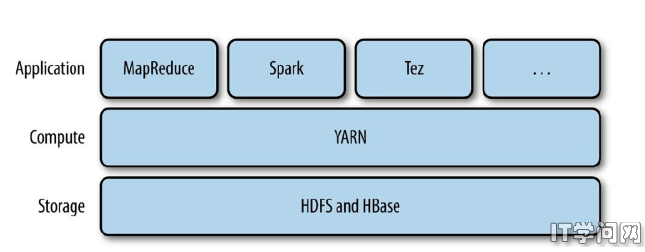
YARN提供请求和使用集群资源的API,应用开发者基本不会用这些api,但这些API很少直接用于用户代码。用户一般代码中用的是分布式计算框架提供的API(像spark API),这些分布式计算框架API建立在YARN之上且向用户隐藏了资源管理细节。下图描述一些分布式计算框架(MapReduce, Spark 等等)作为YARN应用运行在集群计算层(YARN)和集群存储层(HDFS和HBase)上。
2.YARN运行机制
YARN通过两类长期运行的守护进程提供自己的核心服务:
- 管理集群上资源使用的资源管理器(resource manager)、
- 运行在集群中所有节点上且能够启动和监控容器(container)的节点管理器(nodemanager)。
容器用于执行特定应用程序的进程,每个容器都有资源限制(内存、CPU等)。一个容器可以是一个Unix进程,也可以是一个Linux cgroup,取决于YARN的配置。下图描述了YARN是如何运行一个应用的。
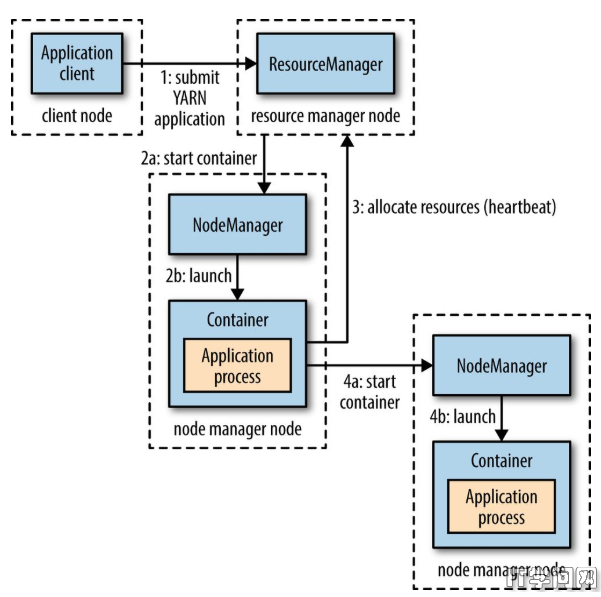
2.1 yarn运行应用步骤
- 客户端联系资源管理器,要求运行一个application master进程(上图步骤1)。
- 资源管理其找到一个能够在容器启动application master的节点管理器(上图步骤2a、2b)。
- application master运行后,根据应用本身向资源管理器请求更多容器(上图步骤3)。
- 资源管理器给application master分配需要的资源后,application master在对应资源节点管理器启动容器,节点管理器获取任务运行需要的resources后,在该容器运行任务。(上图4a、4b)。
YARN本身不会为应用的各部分(客户端、master 和进程)彼此间通信提供任何手段。这个是在运行在yarn之上的分布式应用来实现的,大多数重要的YARN应用使用某种形式的远程通信机制(例如Hadoop的RPC层)来向客户端传递状态更新和返回结果。
2.2资源请求的方式
YARN有一个灵活的资源请求模型。当请求多个容器时,可以指定每个容器需要的计算机资源数量(内存和CPU),还可以指定对容器的本地限制要求。
- 本地化对于确保分布式数据处理算法高效使用集群带宽非常重要,因此,YARN允许一个应用为所申请的容器指定本地限制。本地限制可用于申请位于指定节点或机架的容器。
- 有时本地限制无法被满足,这种情况下要么不分配资源,或者可选择放松限制。例如,一个节点由于已经运行了别的容器而无法再启动新的容器,这时如果有应用请求该节点,则YARN将尝试在同一机架中的其他节点上启动一个容器,如果还不行,则会尝试集群中的任何一个节点。
- 通常情况下,当启动一个容器用于处理HDFS数据块(为了在MapReduce中运行一个map任务)时,应用将会向这样的节点申请容器:存储该数据块三个复本的节点,或是存储这些复本的机架中的一个节点。如果都申请失败,则申请集群中的任意节点。
- YARN应用可以在运行中的任意时刻提出资源申请。例如,可以在最开始提出所有的请求,或者为了满足不断变化的应用需要,采取更为动态的方式在需要更多资源时提出请求。
Spark采用了上述第一种方式,在集群上启动固定数量的执行器。而MapReduce 则分两步走,在最开始时申请map任务容器,reduce 任务容器的启用则放在后期。但同样如果任何任务出现失败,将会另外申请容器以重新运行失败的任务。
