1.MapReduce编程模型介绍
Hadoop系统支持谷歌公司发明的MapReduce编程模型,MapReduce模型有两个彼此独立的步骤,这两个步骤都是可以配置并需要用户在程序中自定义:
- Map:数据初始读取和转换步骤,在这个步骤中,每个独立的输人数据记录都进行并行处理。
- Reduce: 一个数据整合或者加和的步骤。在这个步骤中,相关联的所有数据记录要放在一个计算节点来处理。
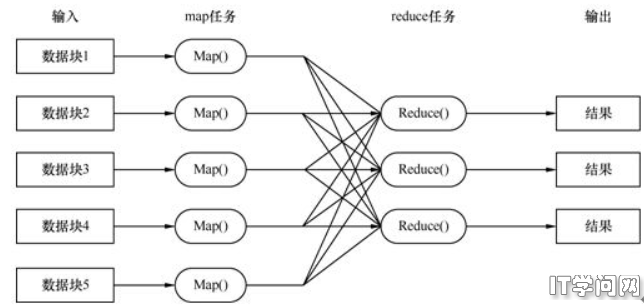
Hadoop系统中的MapReduce核心思路是,将输人的数据在逻辑上分割成多个数据块,每个逻辑数据块被Map任务单独地处理。数据块处理后所得结果会被划分到不同的数据集,且将数据集排序完成。每个经过排序的数据集传输到Reduce任务进行处理。
一个 Map任务可以在集群的任何计算节点上运行,多个Map任务可以并行地运行在集群上。Map任务的主要作用就是把输人的数据记录(inputrecords)转换为一个个的键值对。所有Map任务的输出数据都会进行分区,并且将每个分区的数据排序。每个分区对应一个Reduce任务。每个分区内已排好序的键和与该键对应的值会由一个Reduce任务处理。有多个Reduce任务在集群上并行地运行。
一般情况下,应用程序开发者根据Hadoop系统的框架要求,仅需要关注以下四个类:
- 一个类是用来读取输入的数据记录,并将每条数据记录转换成一个键值对;
- 一个Mapper类;
- 一个Reducer类;
- 一个类是将Reduce方法输出的键值对转换成输出记录进行输出。
2.MapReduce编程案例解析
让我们来使用MapReduce编程模型的“Hello-World"程序:计数程序( the word-countapplication),来示例讲解MapReduce的编程思想。
假设你有海量文本文档。大家现在分析非结构化数据的兴趣越来越浓,这样的情况是比较常见的.现在要统计单词数量,当数据量非常大的时候,我们可以尝试使用MapReduce来解决这个计数问题。
MapReduce实现步骤:
1)首先得有一个hadoop集群,假设50个节点
2)假设现在有一千万个文件,这样会有一千万个Map处理这些文件,一个cpu每次运行一个map(这种假设只是理想型的)。这样50节点集群每台服务器负责运行20万个Map处理,而集群的服务器是8核的CPU,所以8个Mapper可以同时运行,共25 000次迭代。
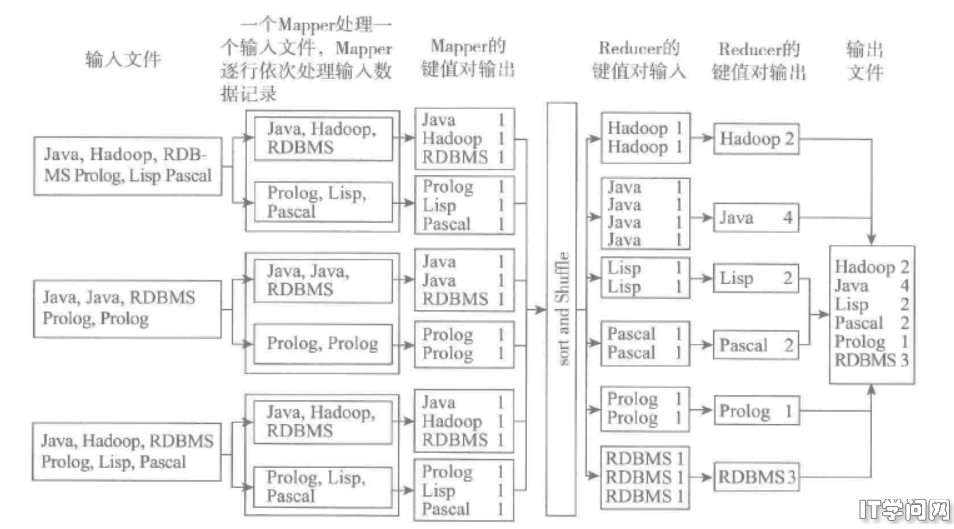
3)每个Mapper处理一个文件,抽取文件中的单词,并输出如下形式的键值对:<{WORD}, 1>。Mapper的输出如下词的映射:<the,1>,<the,1>,<test,1>
4)Reducer会接受如下格式的键值对: <the,[1,1,1...,1]>,<test,[1,1]>。 换句话说,Reducer 任务接受的键值对的构成是,其键为任意一个Mapper输出的单词( <WORD>),其值为任意一个Mapper输出的与键对应的一组值(....1])。
5)Reducer每处理一个相同的单词,就简单地将该单词的计数加1,最终得到了<单词>的总数;然后将结果按照以下键值对格式输出: <{WORD}, { 单词总数}>。Reducer 任务的输出键值对示例如下所示:<the,1000101>,<test,2>
从一个键对应一个值变换成了在Reduce阶段接受的一个键对应一组值,这个过程在MapReduce中称为排序1混洗(sort/shuffle)阶段。由Mapper任务输出的所有键值对在Reducer任务中都按键排序了。如果配置了多个Reducer, 那么每个Reducer 将会处理键值对集合中的某个子集。键值对在由某个Reducer处理之前,就已经按键排序完毕,这确保了相同的键对应的值会由同一个Reducer接受并处理。
Hadoop 系统从系统结构设计上就确保了大多数的Mapper都从本地磁盘读取文件。HDFS的总体设计使得文件对网络传输交换是敏感的,以此来确保计算任务被调度到文件所在的位置来本地执行.
