代理记账业务内部规范(模板) 下载
申请代理记账许可证的《代理记账业务内部规范(模板)》下载 代理记账业务内部规范 一、签订《代理记账委托协议书》 委托人委托本公司进行代理记账时,应当在互相协商的基础上,签订书面委托协议。委托协议除具
modbus4j使用教程
先解释一下什么是modbus协议 Modbus是一种串行通信协议,是Modicon公司(现在的施耐德电气Schneider Electric)于1979年为使用可编程逻辑控制器(PLC)通信而发表。
Spring Security动态权限验证
@Configuration public class WebSerurityConfig extends WebSecurityConfigurerAdapter { @Autowired
javascript异步函数async、await、promise
1.聊一聊javascript同步和异步编程 1.1什么是异步编程 javascript是同步的,根据 你写的代码一步步执行,连引入js文件 都是同步的(除非用async属性),那不废话吗,肯定根
IntelliJ IDEA忽略node_modules索引index
开发前端项目会有node_modules,在idea打开时,idea也会扫描该目录并索引。会导致卡死,node_modules一般都很大,而且一般不需要对其索引。 步骤一:点击 node_modul
react material ui完整教程(jsx)
整个material ui的案例先整javascript的,此教程会包含react和mui的基础知识,后面有需要再搞搞typescript. 先贴一下文档 react官方中文文档:https://
spring security oauth2 jwt rsa非对称加密
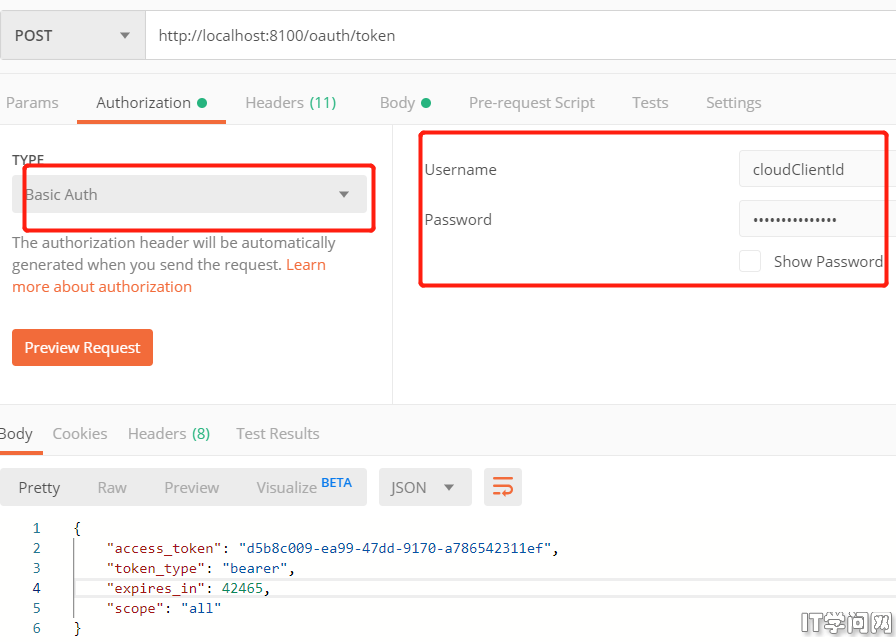
spring security只适合单机,spring security oauth2才是分布式的选择,分布式下我肯定搞jwt,要不然得考虑分布式session,jwt续签问题,不着急,慢慢来。 1
java Lambda表达式彻底学会-未完
先看一下java8的新特性: Lambda表达式 函数式接口 (双冒号) 方法引用与构造器引用 Stream API 接口的默认方法与静态方法 新时间日期API 最大化减少空指针异常
k8s(Kubernetes)教程详细实践-未完
在使用k8s之前我们要先搞清楚几个概念: docker:容器化 docker-compose:在单机上的容器编排 k8s(Kubernetes):集群上的容器编排工具 持续集成:指的是需求-开
关于sentinel基于nacos持久化的rule-type
配置sentinel基于nacos持久化时,有rule-type搞不清楚 sentinel: transport: dashboard: 192.168.56.
sentinel基于nacos使用案例
1.下载sentinel jar https://github.com/alibaba/Sentinel/releases 启动jar nohup java -Dserver.port=901
spring cloud alibaba 之 seata 案例
1.nacos搭建 参考官网https://nacos.io/zh-cn/docs/quick-start-docker.html 下载代码-》mysql执行脚本-》修改 env目录下mysql连
解决feign Consider defining a bean of type
调用feign 接口出现下面找不到bean异常 Consider defining a bean of type 'com.stackcloud.data.api.interfaces.TestD
解决 nacos docker mysql8 no No Datasource set问题
nacos使用官方文档 用docker方式启动,经常出现no No Datasource set,尤其是我 重启虚拟机服务器后,docker容器会自动重启,但是就是no No Datasource s
jenkins使用maven打包报错error: cannot find symbol
1.我本地打包没有任何问题,但是jenkins使用maven打包报错 [ERROR] /var/jenkins_home/workspace/datService.java:[9,15] erro
Jenkins安装Nodejs npm 构建前端
Jenkins安装Nodejs 前端自动化构建执行install、build等命令都要用到Nodejs。在Jenkins安装插件即可使用。 安装Nodejs 1、登录Jenkins系统,点击面包
python selenium webdriver chrom windows打不开网页
1.场景 用python做一个爬虫,测试案例代码 from selenium import webdriver from selenium.webdriver.chrome.service im